Metric Nodes
Metrics provide a quantitative way to evaluate AI model outputs, ensuring you can measure performance against a reference or desired outcome. By adding a metric node to your pipeline, you can automatically calculate scores such as BLEU, ROUGE, or accuracy.
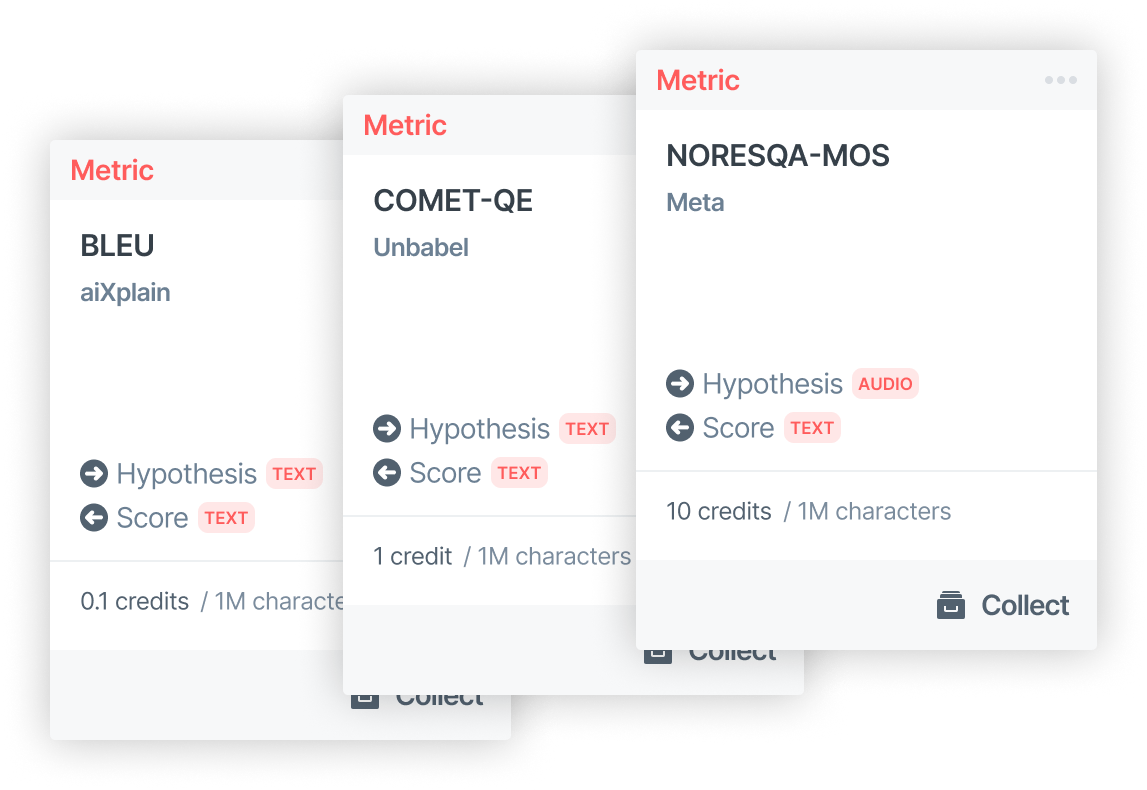
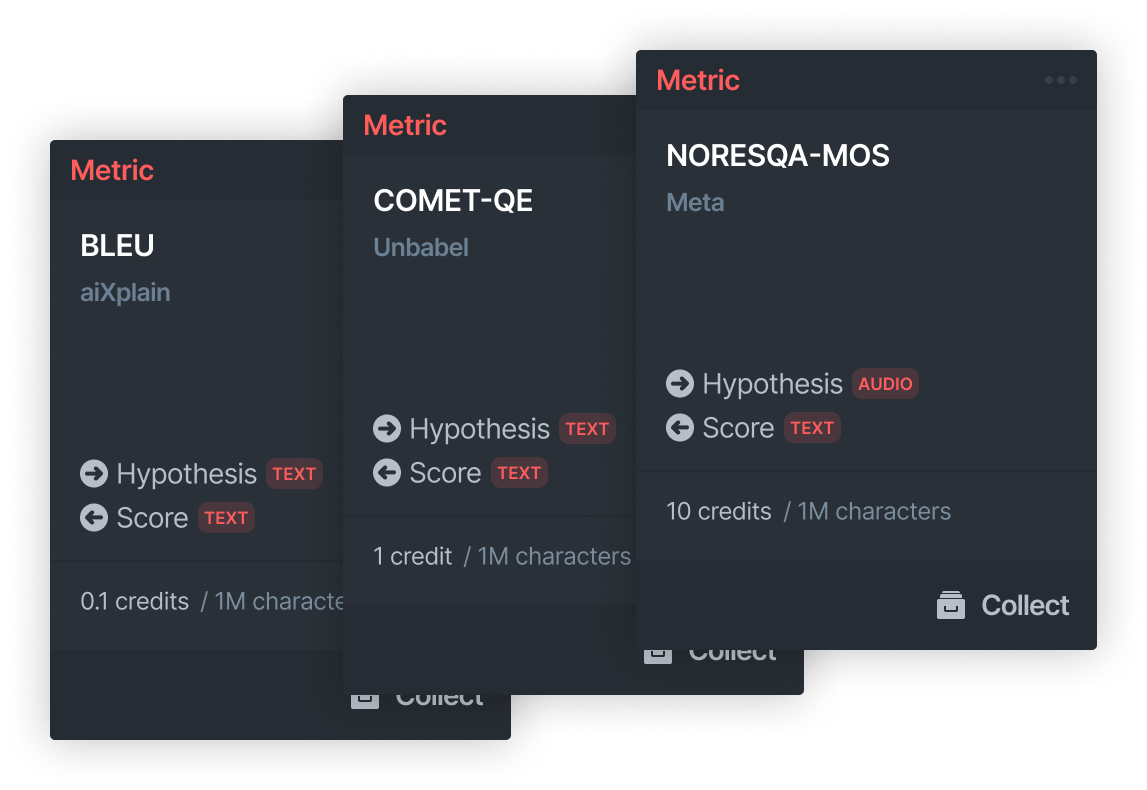
We have reference similarity metrics, human evaluation estimation metrics, and referenceless metrics. We provide a wide range of evaluation metrics, catering to many tasks and modalities. Below are some examples.
Text Generation
- BLEU (Papineni et al., 2002)
- WER (Woodard and Nelson)
- chrF (Popovic´, 2015)
- Comet DA (Reiet al., 2020)
- Nisqa (Mittag et al., 2021)
- Comet QE (Reiet al., 2021)
Speech Recognition
- WIL, MER (Morris et al., 2004)
Machine Translation
- TER (Snover et al., 2006)
- METEOR (Banerjee and Lavie, 2005)
Speech Synthesis
- PESQ (Rix et al., 2001)
- DNSMOS (Reddy et al., 2021)
This example illustrates how to create a pipeline that:
- Accepts two inputs: one for the hypothesis (model output) and one for the reference.
- Uses two metric nodes to evaluate the same hypothesis/reference with different metrics (for example, BLEU and CHRF).
- Ends with output nodes for each metric’s score.
Create the Pipeline
This example pipeline consists of:
- 2 input nodes (for hypothesis and reference text).
- 2 metric nodes (two different metrics).
- 2 output nodes (one for each metric score).
from aixplain.factories import PipelineFactory
from aixplain.enums import DataType
# Initialize a pipeline
pipeline = PipelineFactory.init("Metrics Pipeline Example")
# 2 Input Nodes (hypothesis and reference)
hypothesis_input = pipeline.input(data_types=[DataType.TEXT]) # model output
reference_input = pipeline.input(data_types=[DataType.TEXT]) # ground truth
# 2 Metric Nodes (e.g., BLEU and CHRF)
metric_node_bleu = pipeline.metric(asset_id="YOUR_BLEU_ASSET_ID")
metric_node_chrf = pipeline.metric(asset_id="YOUR_CHRF_ASSET_ID")
# Link Inputs to Metrics
# Typically, metric nodes expect "hypotheses" and "references" params
hypothesis_input.link(metric_node_bleu, 'input', 'hypotheses')
reference_input.link(metric_node_bleu, 'input', 'references')
hypothesis_input.link(metric_node_chrf, 'input', 'hypotheses')
reference_input.link(metric_node_chrf, 'input', 'references')
# Output Nodes for Each Score
bleu_output = pipeline.output()
chrf_output = pipeline.output()
# Link the score param to each output node
metric_node_bleu.link(bleu_output, 'score', 'output')
metric_node_chrf.link(chrf_output, 'score', 'output')
# Save & Run
pipeline.save(save_as_asset=True)
print("Pipeline saved successfully!")
# Provide hypothesis & reference text
result = pipeline.run({
"hypothesis_input": "Hello world",
"reference_input": "Hello world!"
}, version="3.0")
print(result)
Guide to Building the Metrics Example Pipeline
Initialize the Pipeline
from aixplain.factories import PipelineFactory
from aixplain.enums import DataType
# Initialize a pipeline
pipeline = PipelineFactory.init("Metrics Pipeline Example")
Add Input Nodes
We define two input nodes, one for the hypothesis and one for the reference:
hypothesis_input = pipeline.input(data_types=[DataType.TEXT])
reference_input = pipeline.input(data_types=[DataType.TEXT])
hypothesis_input: Accepts the model output text.reference_input: Accepts the ground truth text.
Add Metric Nodes
Each metric node uses a specific metric asset. Here we assume two different metrics:
metric_node_bleu = pipeline.metric(asset_id="YOUR_BLEU_ASSET_ID")
metric_node_chrf = pipeline.metric(asset_id="YOUR_CHRF_ASSET_ID")
Link Nodes
Each metric node typically requires:
hypotheses: The model’s output or candidate translation.references: The ground truth or reference text.
# Link hypothesis & reference to BLEU
hypothesis_input.link(metric_node_bleu, 'input', 'hypotheses')
reference_input.link(metric_node_bleu, 'input', 'references')
# Link hypothesis & reference to CHRF
hypothesis_input.link(metric_node_chrf, 'input', 'hypotheses')
reference_input.link(metric_node_chrf, 'input', 'references')
Output Nodes
To capture the final scores:
bleu_output = pipeline.output()
chrf_output = pipeline.output()
metric_node_bleu.link(bleu_output, 'score', 'output')
metric_node_chrf.link(chrf_output, 'score', 'output')
This ensures both metric scores are returned when the pipeline runs.
Validate the Pipeline
Check that:
- The pipeline has input nodes for hypotheses and references.
- Each metric node is linked correctly to these inputs.
- Each metric node outputs a score linked to an output node.
Then, save the pipeline. Any linking issues or param mismatches will raise an error.
pipeline.save()
Run the Pipeline
Pass both inputs as a dictionary:
result = pipeline.run({
"hypothesis_input": "Machine translation output",
"reference_input": "Reference text"
}, version="3.0")
print(result)
You’ll see two final outputs, each containing the metric score.
Using metric nodes allows you to seamlessly integrate performance evaluation into your pipelines. This provides a comprehensive, automated workflow that covers both AI generation and robust evaluation.