Overview
Models
aiXplain has an ever-expanding catalog of ready-to-use AI models by different suppliers (e.g. AWS, Microsoft, Google, Meta, etc.) for various functions (e.g. Machine Translation, Speech Recognition, Large Language Modeling, Sentiment Analysis, etc.). These models are available on-demand, can be connected together into Pipelines and Agents.
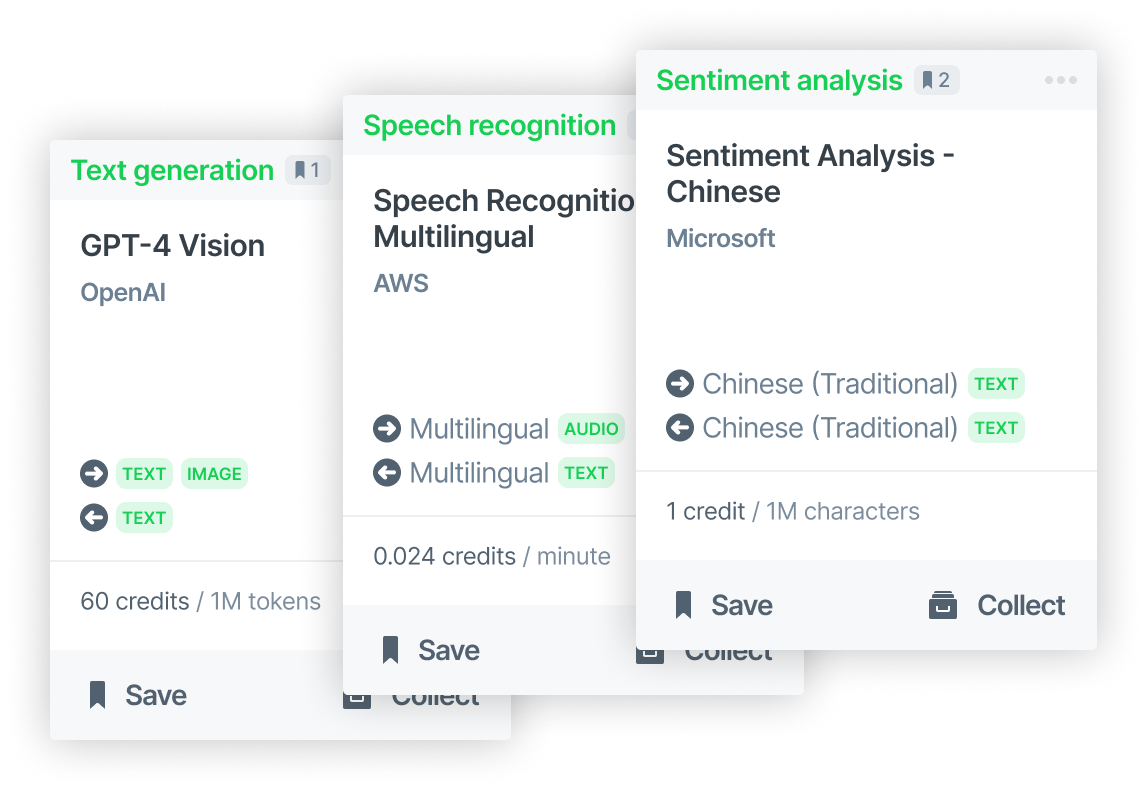
Curation
aiXplain's models are categorized using several filters, such as Function, Supplier and Modalities (e.g. source language, target language) to make searching easier.
Standardization
All aiXplain models can be run using the same syntax via the SDK, and our standardizations allow for model swapping in your pipelines.
Onboarding
You can onboard your own models onto aiXplain, making them accessible for deployment and utilization within your applications.